| allunaggio.mp3 | ||
| json2srt.py | ||
| README.md | ||
| sboby-custom-action.png | ||
| sboby.jpg | ||
{kind=link}
{kind=link}
sboby - Trascrivere una registrazione audio
"Sbobinare, parola amara". Anonimo, De Labore Bastardo. Senzatempo ed.

Sbobinare - v. tr. riportare per iscritto il contenuto di discorsi, interviste, conferenze registrati su nastro magnetico.
Si usa raramente il nastro magnetico, ma si lavora comunque a comporre un testo da un audio, un file digitale come WAV, OGG o MP3.
Di seguito una breve guida pratica per implementare la trascrizione automatica di audio sul proprio Pc, funzionante anche senza collegamento internet perché il modello linguistico verrà scaricato e usato localmente, in autonomia.
Nota: La trascrizione sarà esatta circa al 90% e si raccomanda dunque, prima di pubblicare, di ascoltare l'audio leggendo la trascrizione ottenuta in modo da poter correggere gli errori. Ad esempio per individuare delle frasi di senso compiuto, ma che non sono mai state dette, cioé le cosiddette: "allucinazioni". Anche i nomi propri di persona non possono venir riconosciuti e vengono approssimati. Certamente una dettatura scandita nel microfono otterrà risultati migliori di un audio ambientale mentre in sottofondo friggono mistiche patatine fritte. E dunque seppure riascoltar si deve, il testo ricavato autonomaticagigamente risulterà una buona base e andrà ad alleviare il lavoraccio di trascrizione.
tl;dr non ti fidare e riascolta l'audio mentre rileggi.
Useremo il Vosk speech recognition toolkit: https://alphacephei.com/vosk/
Debian GNU/Linux OS libero: https://www.debian.org/
Un file audio: 
Sono supportati sia MP3 che WAV che OGG e AAC.
Elenco delle operazioni
Partiamo da GNU/Linux, Debian 12 (stabile).
nota: qualsiasi OS con un ambiente python3 funzionante andrà bene, questa guida usa Debian 12.
Andiamo a installare python e altre cose utili:
$ sudo apt install python3 python3-full python3-venv ffmpeg unzip mediainfo
Creiamo la cartella: "sboby" e al suo interno, la sotto-cartella: "vosk":
$ mkdir -p ~/sboby/vosk
Entriamo nella cartella sboby/vosk/:
$ cd ~/sboby/vosk/
Scarichiamo il modello, anche LLM, vosk-italiano, circa 2GB:
$ wget https://alphacephei.com/vosk/models/vosk-model-it-0.22.zip
Altre lingue sono scaricabili alla pagina dei Vosk models.
Scompattiamo il modello appena scaricato:
$ unzip vosk-model-it-0.22.zip
Opzionale: possiamo ora cancellare il file zip:
$ rm vosk-model-it-0.22.zip
Usciamo dalla cartella ~/sboby/vosk/:
$ cd
Creiamo un ambiente virtuale per Python:
$ python3 -m venv /home/$USER/sboby
Usiamo Python per scaricare e installare wheel (una libreria necessaria) e vosk-transcriber:
$ ./sboby/bin/pip3 install wheel
$ ./sboby/bin/pip3 install vosk
Ora possiamo effettuare la prima trascrizione, useremo ad esempio l'audio
Prima, vediamo quanto dura:
$ mediainfo allunaggio.mp3 | grep Duration
Duration: 1 min 16 s
A seconda delle risorse disponibili, varierà il tempo di elaborazione. Per un Pc di media potenza, un audio di 1 ora, potrebbe impiegare circa 1 ora.
Possiamo ora invocare il programma: "vosk-transcriber", indicando (-i) quale audio sbobinare, che modello usare (--model) e dove (-o) appoggiare il testo.
$ ~/sboby/bin/vosk-transcriber -i ~/sboby/allunaggio.mp3 --model /share/software/vosk/vosk-model-it-0.22/ -o ~/sboby/allunaggio.txt
Possiamo anche ottenere la trascrizione in formato testo sottotitolo (SRT) con time-code:
$ ~/sboby/bin/vosk-transcriber -i ~/sboby/allunaggio.mp3 --model /home/$USER/sboby/vosk/vosk-model-it-0.22/ -t srt -o ~/sboby/allunaggio.srt
Opzionale: Possiamo mettere tutto nello script sboby.sh in ~/bin/ che renderemo eseguibile (chmod 755 ~/bin/sboby.sh):
#!/bin/sh
~/sboby/bin/vosk-transcriber -i ${1+"$@"} --model ~/sboby/vosk/vosk-model-it-0.22/ -o ${1+"$@"}.txt ;
sleep 5s ;
~/sboby/bin/vosk-transcriber -i ${1+"$@"} --model ~/sboby/vosk/vosk-model-it-0.22/ -t srt -o ${1+"$@"}.srt
echo 'bye bye sboby'
In modo da ottenere la trascrizione tramite il semplice comando: sboby.sh [FILE]..
$ sboby.sh allunaggio.mp3
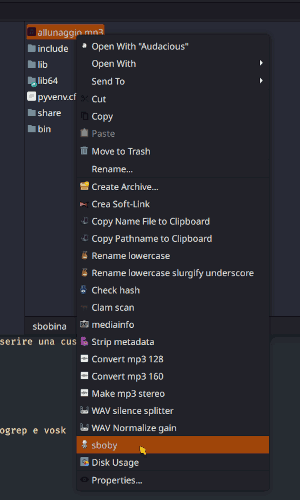
Infine, se usiamo XFCE4 come ambiente scrivania, si potrà inserire una custom action in Thunar da usare cliccando col tasto destro sull'audio:
/home/$USER/bin/sboby.sh %f
Share and enjoy
"Dove si smangiuca, dio mi conduca. Dove si lavora, non venga mai l'ora". Skiantos, 2009, Una vita spesa a skivar la fresa.
Commenti? Kudos? Consigli? Vaffa? Grazie! -- dan [at] autistici [dot] org
Prima versione: 2022-06-06
Ultimo aggiornamento: 2024-09-04
bye bye sboby